
943681188@qq.com
AlphaGo的八个问题,你想知道吗?
从北京时间3月9日12:00整到目前为止,举世瞩目的围棋“人机世界大战”仍在上演着。
战况激烈,似乎牵动着全世界的各色眼光,而关于这场世纪大战,有8个问题你需要知道。
为什么要研究围棋AI?
游戏,是AI最初开发的主要战地之一。博弈游戏要求AI更聪明、更灵活、用更接近人类的思考方式解决问题。游戏AI的开发最早可以追溯到1952年的一篇博士论文。1997年,国际象棋AI第一次打败顶尖的人类;2006年,人类最后一次打败顶尖的国际象棋AI。欧美传统里的顶级人类智力试金石,在电脑面前终于一败涂地,应了四十多年前计算机科学家的预言。

但有一个游戏始终是人类大脑的专利——古老的围棋。 围棋AI长期以来举步维艰,顶级AI甚至不能打败稍强的业余选手。这似乎也合情合理:国际象棋中,平均每回合有35种可能,一盘棋可以有80回合;相比之下,围棋每回合有250种可能,一盘棋可以长达150回合。这一巨大的数目,足以令任何蛮力穷举者望而却步——而人类,我们相信,可以凭借某种难以复制的算法跳过蛮力,一眼看到棋盘的本质。
研究下棋AI,需要研究人员的下棋水平很高吗?
不需要。AlphaGo背后是一群杰出的计算机科学家,确切的说,是机器学习(machine learing)算法领域的专家。科学家利用神经网络算法,将棋类专家的比赛记录输入给计算机,并让计算机自己与自己进行比赛,在这个过程中不断学习训练。某种程度上讲,AlphaGo的棋艺不是开发者教给他的,而是自学成才。

不过,研究出AlphaGo的(Deepmind)创始人 杰米斯•哈萨比斯(Demis Hassabis)确实是棋类的狂热爱好者,哈萨比斯四岁开始接触国际象棋,并很快进化成神童级人物。正是在博弈游戏上的兴趣让哈萨比斯开始思考两个重要问题:人脑是怎样处理复杂信息的?更重要的,电脑也可以像人类一样吗?博士期间的哈萨比斯选择了学习认知神经科学和计算机神经科学。今天,38岁的哈萨比斯带着他的AlphaGo,向人类最顶级的博弈游戏之一——围棋发起进攻。
AlphaGo算法里的“神经网络”是个啥?
AlphaGo 的核心是两种不同的深度神经网络。“策略网络”(policy network)和 “值网络”(value network)。它们的任务在于合作“挑选”出那些比较有前途的棋步,抛弃明显的差棋,从而将计算量控制在计算机可以完成的范围里——本质上,这和人类棋手所做的一样。
其中,“值网络”负责减少搜索的深度——AI会一边推算一边判断局面,局面明显劣势的时候,就直接抛弃某些路线,不用一条道算到黑;
而“策略网络”负责减少搜索的宽度——面对眼前的一盘棋,有些棋步是明显不该走的,比如不该随便送子给别人吃。
AlphaGo利用这两个工具来分析局面,判断每种下子策略的优劣,就像人类棋手会判断当前局面以及推断未来的局面一样。这样AlphaGo在分析了比如未来20步的情况下,就能判断在哪里下子赢的概率会高。
今天AlphaGo和过去的深蓝,谁更厉害?
我们先来看看围棋和国际象棋之间有什么差别:
第一,围棋每一步的可能下法非常多:围棋手在起手时就有19X19=361种落子选择,在比赛的任意阶段,也都有数以百计的可能下法。但国际象棋的可能下法通常只有50种左右。围棋最多有3^361种局面,这个数字大概是10^170,而已经观测到的宇宙中,原子的数量才10^80。国际象棋最大只有2^155种局面,称为香农数,大致是10^47。
第二,对国际象棋来说,只需要把目前棋盘上剩余棋子的价值总和算出来,就能大概知道棋盘上谁处于优势了。但这种方法对围棋来行不通,在围棋的棋局中,计算机很难分辨当下棋局的优势方和弱势方。
可见,同样是下棋,对付围棋要比对付国际象棋棘手得多。
让我们直观的看一下国际象棋和围棋的复杂度对比,上图是国际象棋,下图是围棋:
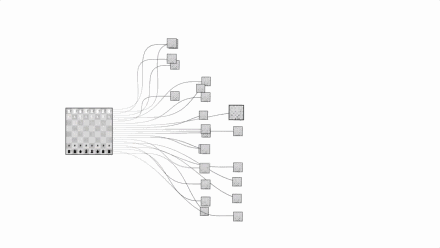
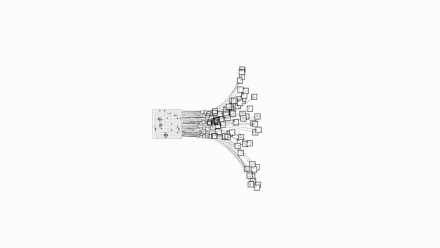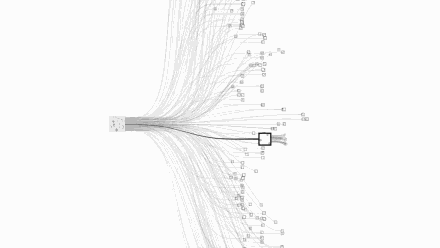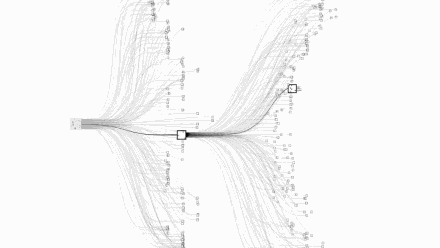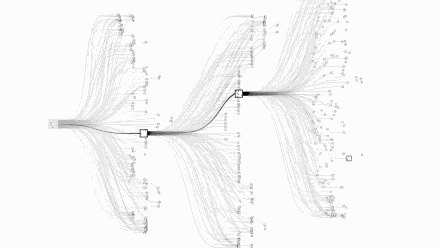 图片来自Google
图片来自Google
另外深蓝就是专门制造出来下国际象棋的。它评估盘面的标准完全依赖于国际象棋本身的规则,除了下棋它就干不了别的了,连五子棋都不会!但AlphaGo不同,围棋只是他的一个测试平台。工程师可以通过围棋,发展和测试AlphaGo的能力。这个能力将来会运用到各个领域。就像《星际争霸》还是角色扮演游戏中的NPC,高级人工智能不仅能成为强有力的对手,也可以变成优秀的团队伙伴。
在战胜樊麾之后的5个月里,AlphaGo都在干嘛?它可能在哪些方面“进化”?
有关AlphaGo在这几个月的“进化程度”,谷歌官方并没有给出任何确切的介绍。但是有位名叫安德斯·可鲁夫(Anders Kierulf)的围棋游戏设计师给出了这样的猜测:
在深蓝对战卡斯帕罗夫的过程中,工程师们可以在比赛间调整深蓝的算法,比如修复bug。对AlphaGo来说,这可能并非易事。比如说,对战樊麾时,第二局的31步是AlphaGo的失误:
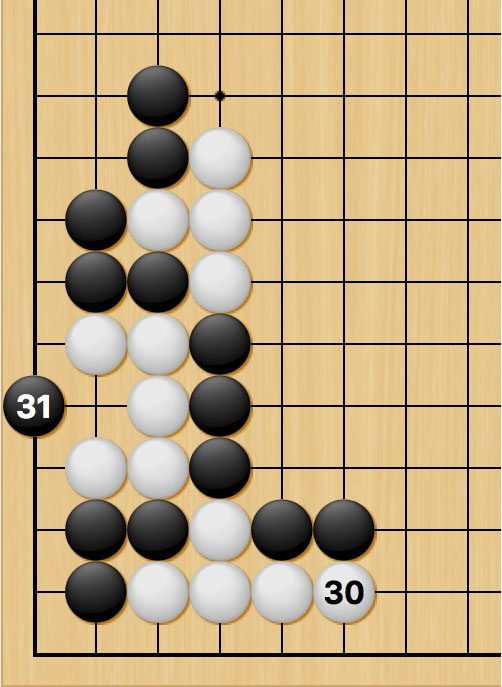
要是换了别的场景,那么这步棋是正确的局部着法——但AlphaGo对全局整体的理解还不够充分。在这种情况下,避免特定的错误则更容易一些。在去年十月,AlphaGo并没有使用开放的库,但在三月的比赛前,Google大可以把库添加进去,至少可以在比赛间调整(如果一盘棋里走错,就在下一盘前手动添加,这样下一盘棋就不会再错),这样李世石就无法连续几盘利用同一个定式错误。
在比赛前,Google可以做的改进还有:
-
改进AlphaGo的神经网络。在对樊麾的比赛中,他们使用了3000万个位置作为原始数据,来训练AlphaGo的价值网络。在对李世石的位置中,他们可以使用1亿个位置训练。
-
额外训练AlphaGo的投骰(rollout)策略,然后将改进过的投骰策略加入到价值网络的训练中。
-
调整投骰和价值网络之间的平衡,也可以在比赛本身中投入更大的运算量。
AlphaG的超强学习能力有没有上限?
对于这个问题,英国曼彻斯特大学计算机科学教授凯文·柯伦表达了否定态度。他认为,我们没有理由相信技术会有极限,特别是在AlphaGo这样的特定领域。
 对战的最后时分。之后,李世乭投子认输。
对战的最后时分。之后,李世乭投子认输。
而来自南京大学计算机系的两位专家,周志华和俞扬则都认为,上限是客观存在的。周志华表示,“强化学习”奏效的关键,是两个模型都不错,而且有足够大的“差异”。当模型性能提升以后,其差异会显著下降,到了一定程度必然会使性能无法继续通过这种机制提升。其上限取决于高质量“有标记”样本(相当于真实李世乭水平棋手的棋局)的数量。
俞扬的观点是,上限不仅存在,而且已经和AlphaGo当下的水平极其接近。从AlphaGo的报道来看,DeepMind已经在想办法避免过拟合(即越学越差),这说明他们可能已经碰到了上限。
如果AlphaGo以5:0战胜李世乭,对人工智能而言意味着什么?
无论最终的结果如何,都无法阻止更多的人类终于开始用警惕的目光打量AI……围棋职业八段刘菁的评论是:“还来不及反应,一切来的似乎是太快了!面对毫无表情,连厕所都不上的阿尔法狗,4000年围棋的终结者今天就来了吗?空气中弥漫着机器的味道。”
就算AI输了,难道你们就松口气了吗?
TOP
- 娱乐淘金/
- 行业/
- 政策/
- APP

热门话题
-
网红产品“遛娃神器”被曝存隐患 网购平台仍在售
 央视《每周质量报告》曝光被称为“遛娃神器”的儿童轻便童车,抽...
央视《每周质量报告》曝光被称为“遛娃神器”的儿童轻便童车,抽...
互联网技术
-
事关生死:在医院ICU病房里人工智能可以做什么?
 在医院的重症监控病房(简称ICU)当中,病情严重的患者需要全天连...
在医院的重症监控病房(简称ICU)当中,病情严重的患者需要全天连...
电商

最新科技
-
很远的地方:清晰视界保卫战
 文质彬彬的书生,气质非凡的才女,在从前人们的印象里无一不带着...
文质彬彬的书生,气质非凡的才女,在从前人们的印象里无一不带着...
资讯视频
 财经 京东吞下1号店 刘强东打的什么算盘?今天凌晨,国内电商企业京东商城和沃尔玛宣布达成一系列深度战略合作。通过整合双方在电商和零售领域的巨大...
财经 京东吞下1号店 刘强东打的什么算盘?今天凌晨,国内电商企业京东商城和沃尔玛宣布达成一系列深度战略合作。通过整合双方在电商和零售领域的巨大... 习近平视察“互联网之光”博览会国家主席习近平16日在浙江省乌镇视察“互联网之光”博览会。习近平强调,互联网给人们的生产生活带来巨大变...
习近平视察“互联网之光”博览会国家主席习近平16日在浙江省乌镇视察“互联网之光”博览会。习近平强调,互联网给人们的生产生活带来巨大变... 他花了百万美元,买下色情网站,为了造飞碟!“飞碟音响”的想法,来自于Allen(张海星)和好朋友Steven(朱田俊)一次在港式茶餐厅的闲聊。他们看见一...
他花了百万美元,买下色情网站,为了造飞碟!“飞碟音响”的想法,来自于Allen(张海星)和好朋友Steven(朱田俊)一次在港式茶餐厅的闲聊。他们看见一... 京东618用30架无人机表演高科技飞行秀近日,为迎接京东618全民购物的狂欢节,京东数码携手亿航无人机在北京上演了一场与众不同的无人机编队表演,...
京东618用30架无人机表演高科技飞行秀近日,为迎接京东618全民购物的狂欢节,京东数码携手亿航无人机在北京上演了一场与众不同的无人机编队表演,... 华为荣耀8曝光 小米自行车发布华为荣耀8曝光 小米自行车发布 富士康收购夏普 魅族又要办演唱会
华为荣耀8曝光 小米自行车发布华为荣耀8曝光 小米自行车发布 富士康收购夏普 魅族又要办演唱会